
¿Qué es un transformer?
Qué había antes del transformer, las tres paredes contra las que nos estrellábamos, y la cuenta paso a paso de cómo funciona la atención por dentro.


En 2008 defendí una tesis doctoral en la que trabajaba con modelos de lenguaje. No es una errata. El transformer llegó nueve años después; ChatGPT, catorce. Los modelos de lenguaje no los inventó Google ni OpenAI: cuando yo peleaba con ellos en la universidad ya eran una herramienta veterana, y la idea de fondo tenía medio siglo.
Lo que pasa es que aquellos modelos no se parecían casi en nada a lo que hoy llamamos modelo de lenguaje. Los nuestros contaban palabras. Literalmente: contaban cuántas veces aparecía cada palabra junto a cada otra en una colección de documentos y, con esas cuentas, calculaban probabilidades. No escribían. No conversaban. En mi caso, servían para algo mucho más modesto: que un buscador entendiera un poco mejor lo que le estabas pidiendo.
Entre aquel mundo y el de ahora no hay una evolución suave. Hay un invento concreto, con fecha y con nombre, que se cargó de golpe las tres limitaciones contra las que nos estrellábamos todos: el transformer. Prometí contarte cómo funciona por dentro y hoy toca pagar esa deuda. Pero para que veas por qué es tan bueno, primero tengo que enseñarte lo que había antes.
La era de contar: medio siglo apostando a la siguiente palabra
Un modelo de lenguaje es, en esencia, una máquina de apostar. Le das un trozo de texto y te devuelve una probabilidad para cada palabra que podría venir después. Eso es todo. Esa definición vale para lo que yo usaba en 2008 y vale, palabra por palabra, para GPT-5 o Claude. Lo que ha cambiado —brutalmente— es cómo se calcula esa apuesta.
La idea es más vieja que el ordenador personal. En 1948, Claude Shannon ya generaba texto sintético usando estadísticas de pares y tríos de palabras, y en 1951 publicó un experimento precioso: pedía a personas que adivinaran la siguiente letra de un texto, una y otra vez, y con sus aciertos midió cuán predecible es el inglés. La conclusión que nos legó es la piedra sobre la que se construyó todo lo demás: el lenguaje es estadísticamente predecible, y esa predictibilidad se puede medir y explotar.
¿Y cómo se explotaba? Contando. Los modelos cuando yo hice la tesis eran modelos de n-gramas: recorres una colección enorme de documentos y cuentas cuántas veces aparece cada secuencia de dos palabras, de tres palabras. Con esas cuentas, la apuesta es una división de primaria.
Hagamos la cuenta de la vieja. Imagina un corpus de juguete con tres frases: “el perro come”, “el perro ladra”, “el gato come”. ¿Qué viene después de “el”? Lo hemos visto tres veces: dos veces “perro”, una vez “gato”. Apuesta: P(perro | el) = 2/3 ≈ 0,67 y P(gato | el) = 1/3 ≈ 0,33. ¿Después de “perro”? Una vez “come”, una vez “ladra”: 0,5 y 0,5. Ya está. Ya tienes un modelo de lenguaje. Es exactamente esto con miles de millones de frases en vez de tres.
Fíjate en un detalle que será importante luego: para apostar por la siguiente palabra solo miras una o dos palabras hacia atrás. Es la asunción de Markov: asumir que el pasado lejano no importa, solo lo inmediato. No es que creyéramos que el resto de la frase no importaba — es que contar secuencias más largas era inviable: casi ninguna secuencia de cinco palabras se repite lo suficiente ni en el corpus más grande del mundo.
¿Y para qué usábamos esto, si no escribía ni conversaba? Entre otras cosas, para buscar. En 1998, Ponte y Croft le dieron la vuelta al buscador con una idea elegante: trata cada documento como un pequeño modelo de lenguaje y ordénalos por la probabilidad de que ese modelo genere tu consulta. En 2001, Victor Lavrenko y Bruce Croft la refinaron con sus relevance models: una distribución de probabilidad sobre todo el vocabulario que describe cómo “suena” lo relevante para tu búsqueda.
Ahí entré yo. Mi tesis (2008) iba de expansión de consultas: cuando escribes “portátil barato”, el sistema añade por su cuenta términos como “ordenador” o “precio” para encontrar documentos que no usan tus palabras exactas. ¿Y cómo decides qué términos añadir y cuáles son ruido? Con cuentas sobre esas distribuciones — entre ellas, la divergencia de Kullback-Leibler, una medida de cuánto se parecen dos distribuciones de probabilidad. Guárdate ese nombre, porque al final del artículo reaparece donde menos te lo esperas.
Y esto funcionaba. Era el estado del arte, movía buscadores reales y daba para tesis doctorales. Pero todos los que trabajábamos en ello chocábamos, una y otra vez, contra las mismas tres paredes.
Las tres paredes (y los parches que les pusimos)
La primera pared era la ventana. La asunción de Markov nos dejaba mirar una o dos palabras hacia atrás, y el idioma se ríe de eso. Piensa en “el perro que adoptamos el año pasado cuando vivíamos en Valencia ___”. Para apostar bien por la siguiente palabra necesitas saber que el sujeto es “perro”; un modelo de trigramas solo ve “en Valencia”. Todo lo que pasara a más de dos palabras de distancia, sencillamente, no existía.
¿Y por qué no contar secuencias más largas? Porque lo intentamos, y la respuesta tiene fecha. En 2006, Google publicó el mayor ejercicio de contar palabras de la historia: el corpus Web 1T, distribuido a través del Linguistic Data Consortium, con las cuentas extraídas de más de un billón de palabras de la web —un millón de millones, el trillion americano—. ¿Hasta dónde llegaron? Secuencias de cinco palabras. Ahí se acabó. Más allá, las combinaciones posibles explotan tan rápido que casi ninguna secuencia concreta se repite lo suficiente como para que contarla signifique algo.
La segunda pared era el cero. Vuelve a nuestro corpus de juguete: nunca vimos “maúlla” después de “perro”, así que P(maúlla | perro) = 0. Cero de verdad: imposible, según el modelo. Y un modelo que asigna probabilidad cero a cosas perfectamente posibles es un modelo roto. El remedio se llamaba smoothing (suavizado): recortar un poco de probabilidad a lo visto y repartirla entre lo no visto. Toda una subdisciplina, con décadas de técnicas cada vez más finas.
Pero fíjate en lo que el smoothing no hace: reparte las migajas a ciegas. Le da la misma probabilidad de rescate a “el gato maúlla” (perfectamente normal) que a “el paraguas maúlla” (absurdo). El parche evitaba el cero, pero no entendía nada.
La tercera pared era la peor: el modelo no sabía que “perro” y “can” se parecen. Para un modelo de n-gramas, cada palabra es un símbolo opaco, una cadena de caracteres distinta de las demás. Todo lo aprendido sobre “perro” no decía nada sobre “can”. Si esto te suena, es porque es exactamente el mundo sin embeddings que vimos hace dos semanas: palabras como casillas aisladas, sin noción de cercanía. Mi tesis entera —la expansión de consultas— era, vista con los ojos de hoy, un parche artesanal contra esta pared: si el sistema no sabe que “portátil” y “ordenador” se parecen, añadámosle las palabras que le faltan a mano, con cuentas.
Y aquí empieza la parte de la historia que va de 2003 a 2017: tres parches, cada uno mejor que el anterior, y cada uno destapando el siguiente problema.
Parche uno: dejar de contar y empezar a aprender. En 2003, Yoshua Bengio y su equipo publicaron el primer modelo de lenguaje neuronal. Dos ideas en una: cada palabra deja de ser un símbolo opaco y pasa a ser un vector aprendido —sí, aquí nacen los embeddings del artículo anterior, nacieron dentro de un modelo de lenguaje—, y una red neuronal aprende a combinar esos vectores para apostar por la siguiente palabra. De golpe, dos paredes se agrietan: si “perro” y “gato” tienen vectores parecidos, lo aprendido sobre uno se transfiere al otro. El modelo generaliza en vez de memorizar. Pero la ventana seguía fija: la red miraba n palabras y punto.
Parche dos: leer en secuencia. Las redes neuronales recurrentes (RNN, recurrent neural networks) leen el texto palabra a palabra, arrastrando un resumen comprimido de todo lo leído — su “estado mental”, se actualiza con cada palabra nueva. En teoría, ventana infinita: adiós a Markov. En la práctica, dos problemas nuevos. Uno: todo lo leído tiene que caber en ese único resumen de tamaño fijo, y claro, en frases largas el principio de la frase se difumina — el resumen es un cuello de botella. Y dos, el que acabaría siendo decisivo: leer en secuencia significa que no puedes procesar la palabra veinte hasta haber digerido las diecinueve anteriores. Imposible de paralelizar. Justo cuando el hardware que despegaba —las GPUs— era bueno en exactamente lo contrario: hacer millones de operaciones a la vez.
Parche tres: dejar mirar atrás. En 2014, Dzmitry Bahdanau, con Cho y Bengio, atacó el cuello de botella en traducción automática con una idea nueva: en vez de obligar al modelo a traducir desde un único resumen comprimido, dejarle mirar todas las palabras de la frase original y decidir cuánto pesa cada una en cada paso. A ese mecanismo de pesos lo llamaron atención. Guarda la fecha: la atención no la inventó el transformer. Nació en 2014, como un parche más, montado encima de una RNN.
Y entonces, en 2017, un equipo de Google se hizo la pregunta que cambió todo: si la atención es la parte que funciona... ¿para qué queremos el resto? Fuera la recurrencia. Fuera la lectura en secuencia. Solo atención. El paper se tituló, literalmente, Attention Is All You Need — la atención es todo lo que necesitas. No fue una invención: fue una sustracción.
Q, K y V: cada palabra pregunta, ofrece y entrega
Recapitulemos dónde estamos. Del artículo de los embeddings sabemos qué entra en el transformer: un vector fijo por token, el mismo para “banco” en “banco del río” que en “banco de inversión”. Y sabemos qué sale: un vector contextual, distinto en cada frase. La pregunta de hoy es qué pasa en medio.
La idea central cabe en una frase: cada palabra mira a todas las demás palabras de la frase y decide cuánto le importa cada una. La atención es el mecanismo que convierte ese “cuánto le importa” en números concretos.
Para conseguirlo, el transformer saca tres versiones de cada token, proyectando su embedding con tres transformaciones aprendidas durante el entrenamiento. Cada versión juega un papel distinto:
La query (consulta): qué estoy buscando. La pregunta que el token le hace al resto de la frase.
La key (clave): qué ofrezco. La etiqueta con la que el token se anuncia ante los demás.
El value (valor): qué entrego. La información que el token cede si alguien decide hacerle caso.
Funciona como un archivador, pero con una diferencia crucial. En un archivador normal, llevas tu consulta, la comparas con las etiquetas de las carpetas, eliges una y te llevas su contenido. En la atención, comparas tu consulta con todas las etiquetas a la vez, le pones una puntuación a cada una, y te llevas una mezcla de todos los contenidos, pesada por esas puntuaciones. Nadie elige una carpeta: se funden todas, cada una aportando según lo bien que su etiqueta casara con tu pregunta.
Hagamos una cuenta sencilla. Tres tokens: banco, del, río. Vectores de juguete de dimensión 2 (los reales tienen miles, pero la aritmética es idéntica). Supongamos que el entrenamiento ya hizo su trabajo y nos dio estas versiones de cada token:
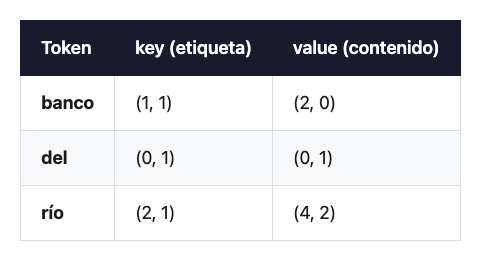
Y la query de “banco” —su pregunta al resto de la frase— es q = (1, 2).
Paso 1: puntuar. La afinidad entre una pregunta y una etiqueta se mide con el producto escalar — la misma cuenta de multiplicar-y-sumar del artículo del coseno:
banco·banco: 1×1 + 2×1 = 3
banco·del: 1×0 + 2×1 = 2
banco·río: 1×2 + 2×1 = 4
“Río” es lo que más le interesa a “banco”. Bien. Pero 3, 2 y 4 son puntuaciones sueltas, no proporciones. (En el transformer real hay aquí un paso de higiene numérica: dividir estas puntuaciones por la raíz de la dimensión de los vectores, para que no se desboquen cuando la dimensión es de miles. Con nuestros vectores de juguete lo saltamos.)
Paso 2: softmax. El softmax convierte una lista de puntuaciones en porcentajes que suman 100%, exagerando las diferencias (los puntos altos se llevan más de lo que proporcionalmente les toca). Softmax(3, 2, 4) = 24%, 9%, 67%. Esto ya se puede leer: para entenderse a sí misma en esta frase, la palabra “banco” decide prestarse un 24% de atención a sí misma, un 9% a “del” y un 67% a “río”.
Paso 3: mezclar. El nuevo vector de “banco” es la mezcla de los tres contenidos, cada uno pesado por su porcentaje:
0,24 × (2, 0) + 0,09 × (0, 1) + 0,67 × (4, 2) = (3,16, 1,43)
Mira lo que acaba de pasar. El vector de “banco” ya no es el que entró: dos tercios de su contenido nuevo vienen de “río”. El embedding fijo se ha convertido en un embedding contextual — este “banco” ya es una orilla, no una oficina. Esa transformación que en el artículo anterior di por hecha (”la atención mueve cada palabra según su contexto”) es exactamente esta suma de tres líneas.
Tres detalles para dejarlo redondo.
Uno: he contado la historia desde “banco”, pero todos los tokens hacen esto a la vez — cada uno lanza su query contra las keys de todos. Cada token se compara con cada token: n², la factura cuadrática del artículo de hace tres semanas. Ahora sabes de dónde sale exactamente.
Dos: a esto se le llama auto-atención (self-attention), porque la frase se mira a sí misma. La atención de Bahdanau de 2014 miraba de la traducción hacia el original; aquí no hay dos textos, hay uno auto-examinándose.
Y tres: todo lo que hemos hecho son multiplicaciones y sumas que no dependen unas de otras — se pueden hacer todas en paralelo. Ni lectura en secuencia, ni resumen arrastrado. Por fin un modelo de lenguaje con la forma exacta que les gusta a las GPUs. Aquí está la verdadera razón por la que el transformer se comió el mundo: no es solo que funcione mejor — es que se entrena millones de veces más a gusto.
Muchas miradas a la vez: multi-head y la torre
Lo que acabamos de calcular es una pasada de atención: una manera de mirar la frase. Pero una frase tiene muchas relaciones a la vez. En “el perro que vimos ayer ladra”, “ladra” necesita encontrar su sujeto (”perro”), pero también le vendría bien saber el tiempo de la acción (”ayer”). Si solo hubiera un juego de pesos, tendría que llegar a un compromiso entre todas esas preguntas — y los compromisos diluyen.
La solución del transformer es no elegir: ejecutar varias atenciones en paralelo, cada una con sus propias transformaciones aprendidas de query, key y value. Cada una se llama cabeza (head), y de ahí el nombre del mecanismo completo: atención multi-cabeza (multi-head attention). El transformer original traía 8 cabezas; cada una desarrolla, durante el entrenamiento, su propia manera de mirar. Al final, los resultados de todas se concatenan y se combinan.
Y esto no es una metáfora bonita: se ha mirado dentro. En 2019, un equipo de Stanford analizó las cabezas de BERT una a una y encontró especialistas nítidos: cabezas que conectan los verbos con sus objetos directos, cabezas que enlazan pronombres con la persona a la que se refieren, cabezas que vinculan cada sustantivo con su determinante. Nadie programó eso. Emergió de predecir palabras.
Falta un ingrediente, porque la atención tiene un punto ciego sorprendente: no sabe en qué orden están las palabras. Las cuentas que hicimos —productos escalares, softmax, mezcla— dan exactamente lo mismo si barajas la frase: para la atención, “perro muerde a hombre” y “hombre muerde a perro” son la misma bolsa de palabras. La solución es directa: antes de entrar al transformer, a cada embedding se le inyecta una señal que codifica su posición en la frase. Los modelos actuales usan variantes más sofisticadas que las de 2017, pero la idea no ha cambiado: el orden no viene de serie — se añade.
Con esto ya podemos montar la pieza completa. Un bloque de transformer son dos paradas: la atención multi-cabeza, donde los tokens intercambian información entre sí, y una pequeña red neuronal (la feed-forward) que procesa cada token por separado, sin mirar a los demás — la etapa donde el modelo aplica lo que tiene memorizado sobre lo que la atención acaba de juntar. Y un detalle de diseño elegante: cada parada suma su resultado al vector que entró, no lo sustituye. Cada bloque retoca; nadie borra.
Ahora, apila. El transformer original de 2017 tenía 6 bloques y unos 65 millones de parámetros. GPT-3, tres años después: 96 bloques, 96 cabezas por bloque, vectores de 12.288 dimensiones, 175.000 millones de parámetros. La receta apenas cambió — cambió la escala. Por cierto: el transformer original traía dos torres, una para leer la frase de entrada y otra para escribir la de salida (nació para traducir). Los GPT se quedaron solo con la torre que escribe. Otra sustracción. Con un matiz importante a la hora de generar: cada token solo puede atender a los que tiene detrás — el futuro todavía no existe.
¿Y arriba del todo, qué hay? La pregunta de siempre. El vector del último token —que a estas alturas ha absorbido contexto de toda la frase, capa tras capa— se proyecta contra el vocabulario entero y un softmax reparte porcentajes: digamos 41% “ladra”, 13% “come”, 9% “duerme”… Es la apuesta de Shannon. La misma de 1951, la misma de mi tesis. Toda esta maquinaria —queries, keys, values, cabezas, bloques— existe para hacer exactamente la apuesta que llevábamos medio siglo haciendo, pero sin las tres paredes: la ventana ya no es de dos palabras sino de todo el contexto; el cero imposible ya no existe porque el modelo generaliza en vez de contar; y “perro” y “can” ya viven al lado en el mapa. No cambiamos de pregunta. Cambiamos de motor.
Lo que supuso de verdad: cómo se construía antes y cómo se construye ahora
Hasta aquí la mecánica. Pero si trabajas en producto o en ingeniería, lo que de verdad importa del transformer no es cómo multiplica vectores: es que cambió la forma de construir sistemas de IA.
Construir un sistema en 2008 era montar una tubería de piezas artesanales. Mi buscador llevaba: un tokenizador con sus reglas, un índice, un modelo de ranking con sus parámetros de smoothing ajustados a mano, y encima mi módulo de expansión de consultas con sus cuentas de KL. Cada pieza, diseñada, ajustada y evaluada por separado. Y cada capacidad era un sistema entero: el traductor automático no compartía ni una línea con el buscador, ni el buscador con el clasificador de spam. ¿Querías una capacidad nueva? Meses de trabajo de un equipo especializado, para esa capacidad y solo esa.
El conocimiento estaba en nosotros, no en el sistema. El sistema solo contaba; el ingeniero decidía qué merecía la pena contar.
El transformer colapsó la tubería entera dentro de una sola pieza. Un único modelo, entrenado con un único objetivo —la apuesta de Shannon, a escala industrial—, y las capacidades emergen: el mismo modelo traduce, resume, clasifica, responde y escribe código, sin que nadie haya construido un sistema para cada cosa. Primero llegó el fine-tuning (ajustar el modelo preentrenado a tu tarea con relativamente pocos ejemplos); luego, algo aún más barato: el prompting — pedírselo. La capacidad que en 2008 costaba un equipo y un año, hoy se alquila por API y se prueba en una tarde.
Y el trabajo cambió de sitio. Ya casi nadie diseña features ni ajusta parámetros de smoothing: el oficio ahora es curar datos, evaluar resultados y orquestar modelos dentro de productos. No es que haya menos ingeniería — es que la ingeniería subió un piso.
Te debo un reencuentro. Dije que guardaras el nombre de la divergencia de Kullback-Leibler, y aquí está. Después del preentrenamiento, a los modelos se les alinea con preferencias humanas (el famoso RLHF, reinforcement learning from human feedback: aprender de valoraciones de personas qué respuestas son mejores). Durante ese proceso hay un riesgo: que el modelo, persiguiendo la recompensa, se deforme y olvide lo que sabía. ¿La correa que lo impide? Una penalización KL: la misma medida con la que yo elegía términos de expansión en 2008 es hoy lo que mantiene a cada LLM alineado cerca de su modelo base. Dieciocho años después, en el corazón de la máquina que lo cambió todo, sigue la misma cuenta. Los motores caducan; las matemáticas no.
Una última cosa, para que el cuento no quede demasiado redondo: lo viejo no murió. El buscador de Mercadona Tech que conté hace unas semanas lleva por dentro BM25 —primo hermano de los modelos probabilísticos de mi época— trabajando codo a codo con embeddings de transformer, y la mezcla gana a cualquiera de los dos por separado. En producción no gana lo más nuevo: gana lo que funciona.
El motor cambió. La apuesta, no
Hemos cubierto mucho terreno. Empezamos en 2008, en un mundo donde un modelo de lenguaje era una tabla de cuentas: divisiones de primaria sobre miles de millones de frases. Vimos las tres paredes contra las que se estrellaba aquel mundo —la ventana corta, el cero imposible, la ceguera ante los parecidos— y los parches cada vez más ingeniosos que les pusimos, hasta que en 2017 alguien dejó de parchear y restó: fuera recurrencia, fuera secuencia. Solo atención.
Y la atención, vista de cerca, resultó ser tres cuentas que caben en una servilleta: puntuar (cada palabra pregunta a todas las demás), repartir (softmax convierte las puntuaciones en porcentajes) y mezclar (cada palabra se reconstruye con lo que le aportan las otras). Multiplica eso por cabezas, apílalo en bloques, y arriba del todo encontrarás la misma apuesta que Claude Shannon hacía a mano en 1951 y que yo perseguía con mi tesis: ¿cual es la palabra siguiente?
Si te llevas una sola idea, que sea esta: el transformer no cambió la pregunta — construyó el primer motor capaz de responderla mirando todo el contexto a la vez. Por eso lo de 2022 no fue un invento súbito: fue la apuesta de siempre, con medio siglo de paredes derribadas de golpe.
Con esto ya tienes la serie casi completa: el token es la moneda, el contexto es la memoria, el embedding es el mapa, y el transformer es el motor. Queda una pieza que te debo: qué pasa exactamente cada vez que le escribes — el viaje entre que pulsas enter y aparece la primera palabra, y por qué la segunda llega mucho más rápido. Los mecanismos de la inferencia. Será el próximo artículo.
Y te dejo con la pregunta práctica de siempre. Mira tu producto con los ojos de este artículo: ¿cuántas de sus piezas siguen siendo parches artesanales de 2008 —reglas escritas a mano, diccionarios de sinónimos, features ajustadas a ojo— para problemas que hoy un modelo resuelve de una pieza? Yo tardé años en hacerme esa pregunta. Tú puedes hacértela esta semana.
gracias, lo encontre complejo o perdí el hilo, lo leere de nuevo
Excelente explicación, mil gracias por tu esfuerzo en simplificar cajas negras para el resto de mortales José!