
¿Qué es un embedding?
El mapa invisible donde un LLM convierte cada palabra en coordenadas.

Qué es de verdad un embedding, cómo se mide el significado con una cuenta de servilleta, qué cuesta construir el mapa y por qué media IA que usas a diario es, por dentro, la misma búsqueda de vecinos.
Hace dos semanas conté aquí que un modelo de lenguaje (un LLM, large language model) no lee palabras: lee tokens. La semana pasada, que paga una factura cuadrática cada vez que intenta recordarlos. Hoy toca la pieza que faltaba entre las dos, la que casi nadie ve.
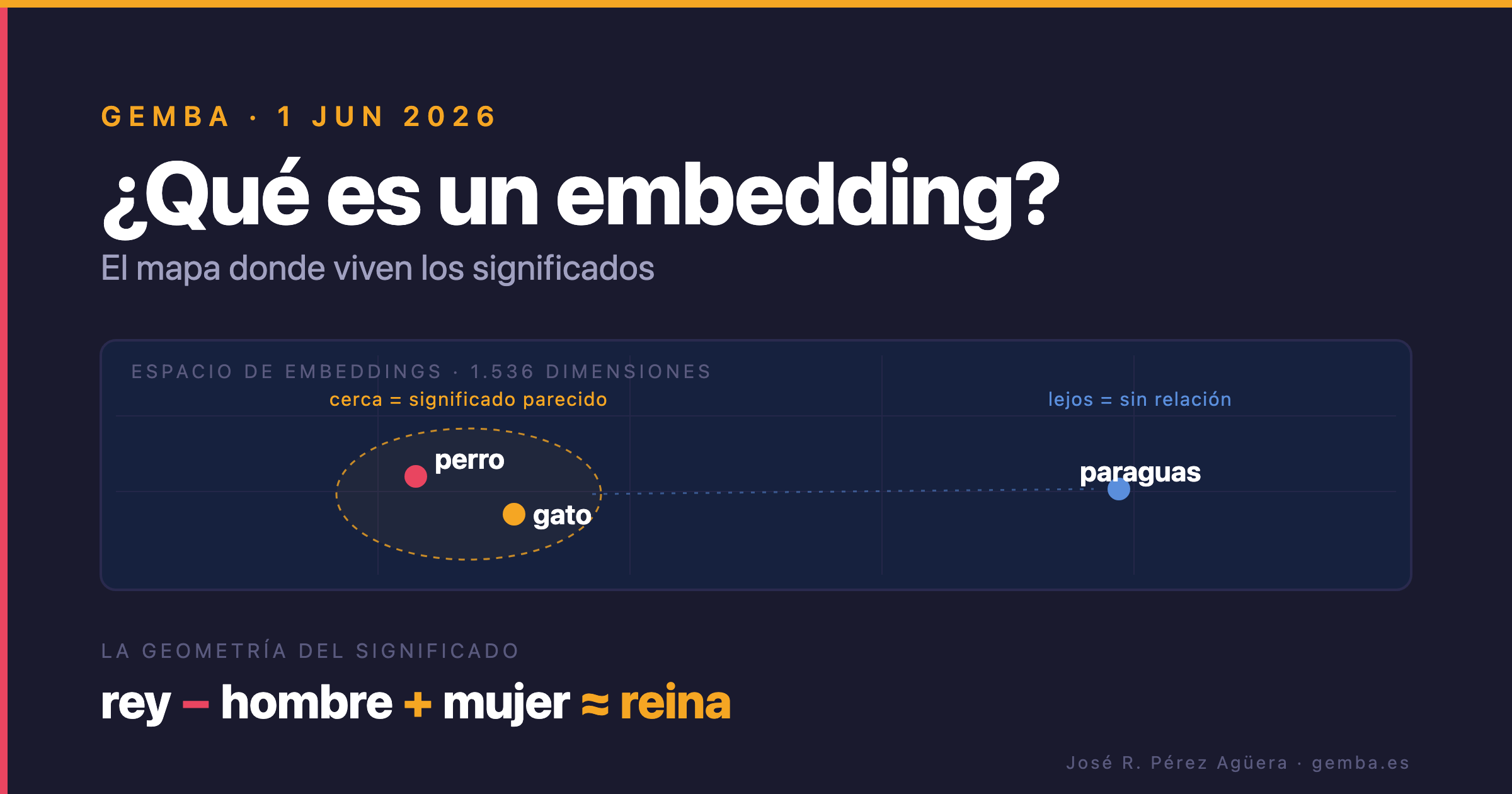
Un token, al final, es un número de serie. El “perro” de tu frase y el “perro” del diccionario acaban siendo el mismo entero en una tabla de vocabulario. Y un número de serie no sabe nada. El 4.521 no está “más cerca” del 4.522 que del 89.000. Si lo único que tuviera un modelo fueran esos identificadores, “perro” y “gato” le resultarían tan ajenos entre sí como “perro” y “paraguas”.
Y sin embargo sabe que no lo son. Sabe que un perro se parece más a un gato que a un paraguas, que “rey” y “reina” comparten algo que “rey” y “lechuga” no. Esa relación no vive en el token. Vive en lo que el modelo hace con él un instante después: convertirlo en una posición dentro de un mapa.
Ese mapa se llama espacio de embeddings. Y aunque llevas dos años recorriéndolo —cada vez que escribes a un chatbot, buscas un producto o recibes una recomendación—, es casi seguro que nunca lo has visto.
Un LLM no entiende palabras. Las convierte en coordenadas. Y casi nadie ha visto el mapa.
Del número al vector: qué es de verdad un embedding
Retrocedamos un paso. Cuando escribes “perro”, el tokenizador parte el texto en tokens y le asigna a cada uno un número: su posición en un vocabulario de, pongamos, 128.000 entradas. Hasta aquí, lo que conté en el artículo del token. “perro” podría ser el 4.521. Un índice. Nada más.
Lo primero que hace el modelo con ese 4.521 es buscarlo en una tabla. Imagina una hoja de cálculo con 128.000 filas —una por token del vocabulario— y unos cuantos miles de columnas. La fila 4.521 es una lista de números decimales: [0,021, −0,87, 0,33, …]. Esa fila es el embedding de “perro”. El número se ha convertido en un vector.
¿Cuántas columnas? Depende del modelo, y los números son concretos:
GPT-2 pequeño: 768
Llama 3 de 8.000 millones de parámetros: 4.096
GPT-3 (175.000 millones): 12.288
Un modelo dedicado a embeddings como text-embedding-3-small de OpenAI: 1.536; su hermano large: 3.072
A ese número se le llama dimensión del modelo (en inglés d_model o hidden size). Es, literalmente, cuántas coordenadas tiene cada palabra en el mapa. “perro” no es un punto en un plano de dos ejes: es un punto en un espacio de 1.536 ejes. Imposible de dibujar, perfectamente real para el modelo.
Dos detalles que lo cambian todo.
El primero: el vector es denso. Todas sus coordenadas tienen un valor, y todas significan algo. La alternativa antigua era el vector one-hot (”uno-caliente”): una lista tan larga como el vocabulario, con un 1 en la posición del token y ceros en las otras 127.999. Ese vector también identifica la palabra, pero es tonto: la distancia entre dos palabras cualesquiera es siempre la misma. No hay geometría. El embedding cambia 128.000 ceros-y-un-uno por 1.536 decimales cargados de información.
El segundo: esos decimales no se programan, se aprenden. Al empezar el entrenamiento, la tabla está rellena de ruido aleatorio. “perro” y “gato” caen en posiciones al azar, sin relación. Pero cada vez que el modelo se equivoca prediciendo la siguiente palabra, mide cuánto y en qué dirección falló, y corrige un poco cada coordenada para fallar menos la próxima vez. Es lo que se llama descenso de gradiente (gradient descent): imagina el error como un paisaje de colinas y valles, y el entrenamiento como bajar a tientas hacia el punto más bajo —o lo que es lo mismo, el lugar donde el error se hace más pequeño—. Millones de pasos después, “perro” y “gato” han migrado a la misma zona del mapa, y “paraguas” se ha quedado lejos. Nadie decidió esas coordenadas a mano. Emergieron de leer texto.
Por eso la tabla de embeddings no es un detalle menor: es una de las piezas más grandes del modelo. La de Llama 3 8B tiene 128.256 filas × 4.096 columnas: más de 500 millones de números solo para la entrada. El mapa pesa.
La hipótesis distribucional: por qué el mapa tiene sentido
Vale, las coordenadas se aprenden. ¿Pero por qué acaban significando algo? ¿Por qué “perro” termina cerca de “gato” y no en una esquina cualquiera?
La respuesta tiene casi setenta años y la formuló un lingüista, no un ingeniero. En 1957, J. R. Firth la dejó en una frase que hoy es el cimiento de todo esto: “You shall know a word by the company it keeps” —conocerás una palabra por la compañía que mantiene—. La idea, que ya rondaba la lingüística de los cincuenta (Zellig Harris la había formalizado en 1954), se llama hipótesis distribucional: el significado de una palabra vive en los contextos donde aparece.
Piénsalo con una palabra que no conozcas. Si lees “anoche me bebí un txakoli muy frío con el pescado”, no necesitas diccionario: las de alrededor —bebí, frío, pescado— ya te han colocado txakoli en la zona de los vinos blancos. Has deducido su posición en el mapa por sus vecinos. Eso es, exactamente, lo que hace el modelo millones de veces sobre todo el texto que lee.
En 2013, un equipo de Google liderado por Tomáš Mikolov convirtió esa intuición en un algoritmo que se hizo famoso: word2vec. La mecánica es de una simplicidad casi insultante: entrena una red para una tarea tonta —dada una palabra, adivinar las que la rodean, o al revés— y, como efecto secundario, los vectores que aprende por el camino capturan el significado. Las palabras que comparten compañía acaban compartiendo coordenadas.
Y entonces apareció el truco que dio la vuelta al mundo. Resultó que en ese espacio se podía hacer aritmética con significados, y conviene verlo en tres pasos. Entrada: coges los vectores de tres palabras —”rey”, “hombre”, “mujer”—. Operación: haces la cuenta con sus coordenadas, restas el de “hombre” y sumas el de “mujer”. El resultado es un vector nuevo: un punto del mapa que no tiene por qué coincidir con ninguna palabra que exista. Salida: buscas qué palabra real cae más cerca de ese punto. ¿Y cuál crees que cae más cerca?
rey − hombre + mujer ≈ reina
El espacio había aprendido, sin que nadie se lo dijera, que existe una dirección que codifica “género” y otra que codifica “realeza”. París − Francia + Italia te deja cerca de Roma. Es genuinamente asombroso: la geometría del mapa esconde reglas que nadie escribió.
Pero no todo es tan bonito como en la teoría, y el punto débil está en el paso de salida. Para decidir qué palabra es el vector resultante, el sistema ordena todo el vocabulario de más cercano a más lejano a ese punto y se queda con el primero. El problema es que las primeras posiciones de esa lista las ocupan, casi siempre, las mismas tres palabras que metiste en la entrada: “rey”, “hombre” y “mujer”. Y tiene su lógica —el resultado se parece muchísimo a sus propios ingredientes—. Así que el método estándar para medir el truco hace una concesión: ignorar las palabras que ya estaban en la operación, que son justo esas tres. Solo cuando las quitas de la lista, la palabra más cercana al vector resultante pasa a ser “reina”. Con esa muleta el acierto se dispara; sin ella, baja mucho (Nissim y otros lo documentaron en 2020). La estructura lineal es real y reproducible, pero es una tendencia estadística, no una ley exacta. El mapa tiene direcciones con sentido; no tiene carreteras perfectamente rectas.
GloVe (Stanford, 2014) llegó poco después con otra receta —contar cuántas veces co-aparecen las palabras en todo el corpus— y resultados parecidos. La conclusión de aquellos años quedó clara: si dejas que un sistema lea suficiente texto obligándole a predecir contexto, la geometría del significado emerge sola. No hace falta enseñarle qué es un perro. Basta con enseñarle dónde suele aparecer la palabra “perro”.
Cosine similarity: cómo se mide el significado
Llevo medio artículo diciendo “cerca”, “lejos”, “vecino más próximo” sin definir qué es la distancia en este mapa. Es hora de la cuenta de la vieja, porque la respuesta es más sencilla de lo que parece y es, literalmente, el motor de todo lo que viene después.
Hay dos formas de medir cuánto se parecen dos vectores.
La primera es la intuitiva: la distancia en línea recta (los matemáticos la llaman euclídea). Pones los dos puntos en el mapa y mides cuánto hay del uno al otro. Funciona, pero tiene un defecto grave para los significados: es sensible al tamaño del vector. Un texto de tres palabras y un documento de mil sobre el mismo tema apuntan hacia la misma zona del mapa, pero uno cae mucho más “lejos del centro” que el otro. En línea recta parecerían distintos cuando hablan de lo mismo.
Por eso casi todo el mundo usa la segunda: la similitud del coseno (cosine similarity). En vez de medir la distancia entre los puntos, mide el ángulo entre las dos flechas que van del origen a cada punto. Si apuntan en la misma dirección, el ángulo es cero y se parecen al máximo. Si son perpendiculares, no tienen nada que ver. Da igual que una flecha sea corta y la otra larga: lo que cuenta es hacia dónde señalan, no cuánto miden.
El resultado es un único número entre −1 y 1:
1 → misma dirección: significados casi idénticos
0 → perpendiculares: sin relación
−1 → direcciones opuestas
Un apunte honesto sobre ese −1, porque es la primera duda que aparece: solo es posible porque los embeddings aprendidos admiten coordenadas negativas. Si tus vectores no pudieran bajar de cero —contar cuántas veces aparece cada palabra, por ejemplo—, el suelo sería 0 y jamás verías un coseno negativo: lo peor sería que no compartieran nada, y eso ya es el ángulo de 90°. Pero hay una sorpresa: en los mapas reales ese extremo −1 apenas se usa. Los vectores tienden a apiñarse en una zona estrecha del espacio, así que casi todos los pares dan positivo, y “significado opuesto” tampoco cae en −1: antónimos como “caliente” y “frío” suelen puntuar alto, porque viven en los mismos contextos. En la práctica lo lees simple: cuanto más positivo, más parecido.
Y se calcula con una cuenta que cabe en una servilleta. Bajemos a un mapa de juguete de solo dos ejes (los de verdad tienen 1.536, pero la operación es idéntica). Tres palabras:
perro = [3, 4]
gato = [4, 3]
paraguas = [−4, 3]
El coseno necesita dos ingredientes. El primero es el producto escalar (dot product): multiplicas coordenada con coordenada y sumas. Perro · gato = 3×4 + 4×3 = 12 + 12 = 24. El segundo es la longitud de cada flecha, que sale del teorema de Pitágoras: la de “perro” es √(3² + 4²) = √25 = 5, y la de “gato”, igual: 5.
El coseno es lo primero dividido por el producto de lo segundo:
coseno(perro, gato) = 24 / (5 × 5) = 24 / 25 = 0,96
Casi 1. Perro y gato apuntan casi en la misma dirección: el mapa los considera muy parecidos. Hagamos ahora “paraguas”:
perro · paraguas = 3×(−4) + 4×3 = −12 + 12 = 0
coseno(perro, paraguas) = 0 / (5 × 5) = 0
Cero. Perpendiculares. Para el mapa, “perro” y “paraguas” no guardan relación. Exactamente la intuición con la que abrí el artículo, ahora convertida en una cuenta que puedes comprobar a mano.
Eso es todo. No hay más magia detrás de “busca lo más parecido”: un producto escalar, dos raíces y una división. Esta cuenta es el motor de la búsqueda semántica, la recomendación y medio sistema de IA que usas a diario —volveré a ella—. Pero antes hay que deshacer una mentira piadosa que llevo arrastrando todo el artículo: he hablado como si cada palabra tuviera un único vector fijo. Y no lo tiene.
El “banco” que cambia: estático contra contextual
La mentira es esta: he dicho que “perro” tiene un vector, en singular. Durante años fue verdad. word2vec y GloVe asignan a cada palabra un único vector fijo, el mismo aparezca donde aparezca. Son embeddings estáticos.
El problema salta a la primera con una palabra como “banco”. ¿El del parque o el de sacar dinero? ¿La orilla del río? word2vec no puede elegir: le da a “banco” un solo vector, que termina siendo una mezcla borrosa de todos sus sentidos. Un punto a medio camino entre el mueble, la entidad financiera y el banco de arena, que no representa bien a ninguno. Lo mismo con “gato” (el animal o la herramienta del coche) o “vela” (la de cera o la del barco).
La solución define la segunda generación de embeddings: los contextuales. La idea es que el vector de una palabra ya no es fijo, sino que se calcula en función de la frase que la rodea. “Me senté en el banco del parque” y “saqué dinero del banco” producen dos vectores distintos para la misma palabra “banco”. El mapa deja de tener una entrada por palabra y pasa a tener una por palabra-en-su-contexto.
¿Y qué máquina hace ese cálculo? El transformer, la arquitectura sobre la que se construyen casi todos los LLMs de hoy. Por dentro lleva un mecanismo llamado atención (attention) que hace algo muy concreto: deja que cada token mire a todos los demás de la frase y absorba parte de su información. El vector de “banco” entra en la primera capa siendo el genérico y borroso del principio; tras pasar por las capas de atención, rodeado de “parque” y “senté”, ha derivado hacia la zona de los muebles; rodeado de “dinero” y “cuenta”, hacia las finanzas. El embedding contextual es lo que sale del transformer, no lo que entra.
Cómo funciona la atención por dentro —el verdadero corazón del modelo— es harina de otro costal, y será el tema del próximo artículo: la siguiente parada de esta serie sobre las tripas de los LLMs (token → contexto → embedding → transformer, y lo que venga después). Hoy nos basta con saber qué hace: convertir un vector fijo en uno que depende de sus vecinos.
Esto no es de ayer. ELMo lo popularizó en 2018 y BERT lo convirtió en estándar en 2019; desde entonces, todo modelo serio trabaja con embeddings contextuales.
Y aquí aparece un tercer significado de “embedding”, probablemente el que te trajo hasta este artículo. Cuando alguien monta un buscador semántico o un sistema de RAG (retrieval-augmented generation, el truco de darle documentos a un LLM para que responda apoyándose en ellos), no guarda un vector por palabra: guarda un solo vector por frase o por documento entero. Coges un párrafo de mil caracteres y lo conviertes en un único punto del mapa de, pongamos, 1.536 coordenadas. Eso es lo que vive dentro de una base de datos vectorial.
Esos vectores los produce un modelo dedicado —un embedding model— que suele ser un pariente de BERT afinado a propósito para que dos textos con el mismo significado caigan cerca. La receta moderna se llama aprendizaje contrastivo: se le enseñan parejas de frases que significan lo mismo y parejas que no, y se le obliga a acercar las primeras y separar las segundas. Sentence-BERT (2019) abrió esa vía; hoy la siguen los text-embedding de OpenAI, los modelos E5, BGE y compañía.
Tres cosas distintas, entonces, bajo la misma palabra: el vector estático de la tabla de entrada, el vector contextual que sale de las capas, y el vector único de una frase entera para buscar. Las tres son embeddings. Y las tres comparten algo que ningún artículo divulgativo suele contar: cuestan dinero. Vamos con la factura.
La factura: lo que cuesta el mapa
Todo el artículo ha tratado el mapa como si fuera gratis. No lo es. Y la factura tiene dos caras muy distintas: lo que cuesta construirlo y lo que cuesta usarlo. La diferencia entre ambas explica buena parte de cómo está montada hoy la industria de la IA.
Construir el mapa: por qué es carísimo aunque el algoritmo sea público
Aquí va la paradoja que más cuesta digerir. Todo lo que te he contado —la tabla de embeddings, el descenso de gradiente, la hipótesis distribucional, la atención— está publicado. Los papers son gratis. El código de referencia, también. Y aun así, casi nadie en el mundo puede construir un modelo de primera línea desde cero. ¿Por qué, si la receta está colgada en internet?
Por tres razones que no salen en el paper.
La primera es el cómputo. El algoritmo es simple; ejecutarlo a escala es un proyecto industrial. Entrenar Llama 3 de 405.000 millones de parámetros le costó a Meta del orden de 16.000 GPUs H100 funcionando durante meses. Sam Altman ha dicho en público que entrenar GPT-4 costó más de 100 millones de dólares. No es el precio de una idea: es el precio de un superordenador encendido sin parar.
La segunda son los datos. Un modelo así se entrena con del orden de 15 billones de tokens (con b: quince millones de millones). Pero no vale texto a granel: hay que recopilarlo, limpiarlo, quitar duplicados, filtrar lo tóxico y lo de baja calidad, y decidir en qué proporción mezclas código, libros, foros o noticias. Esa receta de datos es el secreto mejor guardado de cada laboratorio, y vale más que el propio algoritmo. Dos equipos con el mismo código y distinta dieta de datos producen modelos abismalmente distintos.
La tercera es el conocimiento tácito. Saber qué es el descenso de gradiente no es saber evitar que un entrenamiento de tres meses se descarrile en la semana seis. Hay mil decisiones —ritmo de aprendizaje, inicialización, cómo recuperarte cuando se te muere una GPU a las tres de la madrugada— que no están en ningún paper y se pagan en años de cicatrices. Por cada entrenamiento que sale, hay decenas que acaban en la basura.
Por eso, como conté en el artículo de OSS contra frontera, la pregunta para casi cualquier empresa no es “¿entreno mi propio modelo?”, sino “¿qué mapa alquilo?”. Construirlo desde cero solo tiene sentido para un puñado de actores en el planeta.
Usar el mapa: barato, pero no gratis
La buena noticia: una vez que alguien ha pagado por construir el mapa, recorrerlo es ridículamente barato. Convertir texto en embeddings con un modelo dedicado cuesta céntimos: text-embedding-3-small de OpenAI está a unos 0,02 dólares por millón de tokens. Por el precio de un café embebes una biblioteca.
Pero hay dos costes que asoman en cuanto montas algo de verdad, y conviene tenerlos en el radar.
El primero es el almacenamiento. Un embedding de 1.536 dimensiones, guardado en el formato estándar (decimales de 4 bytes cada uno), ocupa unos 6 KB. Para un documento, nada. Para un millón de documentos: 1.000.000 × 1.536 × 4 bytes = unos 6 GB, solo de vectores. Con cientos de millones de documentos, el mapa deja de caber en memoria y empieza a costar dinero de verdad.
El segundo es la búsqueda. Encontrar el vecino más cercano de forma exacta obliga a comparar tu consulta contra todos los vectores guardados: si tienes 100 millones, son 100 millones de cosenos por cada búsqueda. Inviable en tiempo real. Por eso en producción casi nadie busca exacto: se usan algoritmos de vecino más cercano aproximado (ANN, approximate nearest neighbor), como HNSW o IVF, que renuncian a una pizca de precisión a cambio de respuestas casi instantáneas. El trato de siempre: cambias exactitud por velocidad.
¿Y si 6 GB por millón es demasiado? Una idea reciente y elegante ayuda: los embeddings Matryoshka (por las muñecas rusas), entrenados para que las primeras coordenadas concentren lo esencial. Así puedes quedarte con las primeras 256 de 1.536 y conservar la mayor parte del significado, recortando memoria y coste de búsqueda a voluntad. Los text-embedding-3 ya lo permiten: pides menos dimensiones y pagas menos.
Una última pregunta práctica: ¿qué modelo de embeddings eliges entre los cientos que hay? No a ojo. Existe un ranking público, MTEB (Massive Text Embedding Benchmark), que compara modelos en decenas de tareas reales de búsqueda y clasificación. Es el primer sitio donde mirar antes de casarte con uno.
Lo que te permite hacer: un mapa, mil productos
Aquí está la idea que lo une todo: casi todo lo que hace interesante a un embedding es la misma cuenta del coseno disfrazada. Una vez que puedes convertir cualquier cosa en un punto del mapa y medir distancias, una docena de productos distintos resultan ser el mismo truco con otro nombre. Estos son los principales.
Búsqueda semántica. El buscador de toda la vida casa palabras: si escribes “algo para desayunar” y ningún producto contiene esa frase exacta, no encuentra nada. El buscador semántico casa significados: embebe tu consulta, la compara con los embeddings del catálogo y te devuelve galletas, cereales o tostadas aunque no hayas escrito sus nombres. Es exactamente la capa semántica de SearchMO, el buscador de Mercadona Tech que conté hace unas semanas: BM25 para las palabras, embeddings para el significado, y las dos listas fusionadas.
RAG. Es la aplicación estrella en empresa. Embebes toda tu documentación interna y, cuando alguien hace una pregunta, recuperas los tres o cuatro fragmentos más cercanos a su consulta y se los das al LLM para que responda con ellos en la mano. El embedding es lo que decide qué trozos merece la pena leer. Un RAG bueno o malo casi siempre se juega en la calidad de sus embeddings.
Clasificar y agrupar sin reglas. ¿Quieres ordenar diez mil reseñas por temas, o miles de tickets de soporte por tipo de problema? Antes escribías reglas a mano, una por una. Con embeddings, los textos parecidos caen juntos en el mapa solos, y un algoritmo de agrupación (clustering) te dibuja las categorías sin que tú las definas. Lo mismo para clasificar: “esto se parece a los ejemplos de la categoría X”.
Recomendar y deduplicar. “Parecido a lo que viste” es, literalmente, “cercano en el mapa”. Y al revés: para detectar dos productos duplicados con descripciones distintas, o dos noticias que cuentan lo mismo, buscas vectores casi pegados. Mismo mapa, problema opuesto.
Y un último giro que descoloca la primera vez: los embeddings no son solo de texto. Puedes embeber imágenes, audio o productos enteros. Y puedes entrenar un modelo para que meta texto e imágenes en el mismo mapa: eso hizo CLIP (OpenAI, 2021), y por eso hoy puedes buscar fotos escribiendo “perro en la playa al atardecer” sin que nadie haya etiquetado esa imagen con esas palabras. La palabra y la foto caen en el mismo sitio. El mapa deja de ser de palabras y pasa a ser de conceptos, vengan de donde vengan.
Ese es el patrón mental que merece la pena llevarse: si puedes convertir algo en un vector, puedes buscarlo, agruparlo, clasificarlo y recomendarlo. Y casi todo se puede convertir en un vector.
El mapa que ya usabas
Hemos hecho un viaje corto pero completo. Empezamos con un número de serie sin alma, el token. Lo convertimos en un vector denso: una posición en un mapa de miles de dimensiones. Vimos que ese mapa tiene sentido —que “perro” y “gato” caen juntos— porque el modelo aprendió a colocar cada palabra por la compañía que mantiene. Medimos distancias con una cuenta de servilleta, el coseno. Descubrimos que el mapa no es fijo: la atención mueve cada palabra según su contexto. Le pusimos precio, el de construirlo y el de recorrerlo. Y comprobamos que media docena de productos que usas a diario son, por dentro, la misma búsqueda de vecinos sobre ese mapa.
Si te llevas una sola idea, que sea esta: los embeddings son el punto donde el significado se vuelve geometría. Son la capa silenciosa que hay debajo de la búsqueda que usas, del chatbot al que escribes, de la recomendación que te aparece. Llevas dos años recorriendo ese mapa sin verlo. Ahora ya lo has visto.
Y, como siempre, te dejo con la pregunta práctica: piensa en tu producto. ¿Dónde estás casando palabras exactas cuando deberías estar casando significados? Ese hueco —una búsqueda que no encuentra sinónimos, un soporte que no agrupa tickets parecidos, un catálogo lleno de casi-duplicados— es, casi seguro, un problema de embeddings esperando a que alguien dibuje el mapa.